

はじめに
作った理由とか書いてます。興味ないならこの項目は飛ばしてください。
googleの類似画像検索は、御存知の通り2種類あり、「キーワード検索」と「Search by Image」が出来ます。前者は通常の文字列による検索、後者は検索エンジンに画像を投げて検索するものです。
後者のSearch by Imageも2種類あり、ネット上の画像のURLを投げるものと自前の画像をアップロードするものがあります。どちらかで検索すると以下のように、同じ画像の他のサイズの画像一覧を表示させたり、画像の詳細を調べられます。
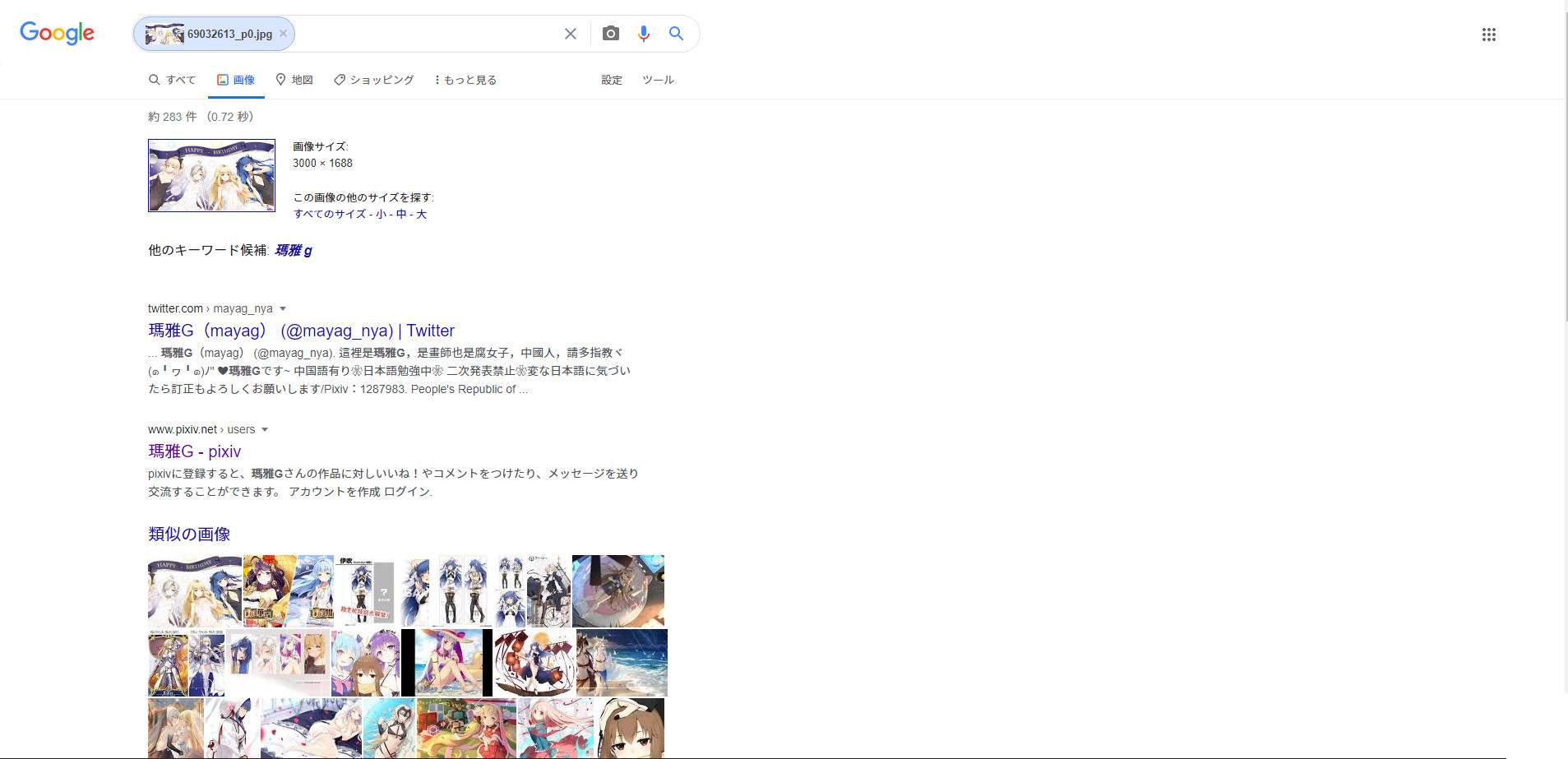
ただ、自前の画像を複数検索する場合は、マウスポチポチ操作で画像を選択して1枚ずつアップロードし検索することになります。そのため一括で画像を検索するってのは非常に面倒くさいのです。そんな訳で表題みたいなプログラムを2種作ってみました。
ここに書いたプログラムを利用して起きるいかなる損害も保障いたしかねます。
また、exeファイルはバグがありそうな予感…
自動検索&自動保存プログラム
ここからダウンロード
マルチプロセス→「search_by_image_multi.zip」
シングルプロセス→「search_by_image.zip」
機能
同階層にある「jpg」「png」ファイルをgoogleのサーバに一括アップロード後、google search by imageの「他のサイズ」から画像を検索。
PIC_NUM(デフォルトで3)枚だけサイズが大きい順にダウンロードし、./large_pic/下に保存します。
もちろん全自動。
えちえち画像も検索できるよ!!!
※Google画像検索の使用上、微妙に異なる画像(文字やロゴや透かしやモザイク入り、差分、トリミング済み)をダウンロードしてくることがあります。それどころかまれに検索結果が有りませんなんてこともあります😭
※画像がリンク切れの場合、壊れた画像を保存します。
※タイムアウトした場合は再接続しません。
※コマンドライン引数を取得しません。
使い方
exeファイルの場合
検索したい画像を同一フォルダに入れたら、同一階層にexeファイルをぶちこんで実行するだけ。
コマンドラインからでなくダブルクリックでも大丈夫です。
pyファイルの場合
コマンドプロンプト等を管理者権限で実行後、↓のコマンドでライブラリをインストールします。
$ pip install -r requirements.txt
インストールできたら、exeファイルと同様に、検索したい画像のディレクトリにソースコードを配置して実行するだけ。
検証環境はPython 3.7.7です。
書き換えて実行する場合の注意点等々
※保存場所は相対パスで記述しています。絶対パスにする場合はsave_pic()内の89,90,92行目の書き換えをお忘れなく。
※サブディレクトリを検索したい場合は、glob.glob()あたりを書き換えてrecursiveオプションを有効にしてください。
※google以外の類似画像検索には使いまわせません。
自動検索&ブラウザキャスト
ここからダウンロード(「search_by_image_webbrowser.zip」)
機能
同階層内の「jpg」「png」ファイルをgoogleのサーバにアップロード後、google search by imageを規定ブラウザで開きます。
次のブラウザを開くにはコマンドラインに何か入力(Enternのみ可)してください。
入力待ちの間に次の画像をアップロードしてるので、実質待ち時間は最初の一枚のみです。
えちえち画像も検索できるよ!!!
※コマンドライン引数を取得しません。
※UAをchromeで書いてるのでchromiumブラウザ推奨かなと思います。
使い方
exeファイルの場合
検索したい画像を同一フォルダに入れたら、同一階層にexeファイルをぶちこんで実行するだけ。
コマンドラインからでなくダブルクリックでも大丈夫です。
pyファイルの場合
コマンドプロンプト等を管理者権限で実行後、↓のコマンドでライブラリをインストールします。
$ pip install -r requirements.txt
インストールできたら、exeファイルと同様に、検索したい画像のディレクトリにソースコードを配置して実行するだけ。
検証環境はPython 3.7.7です。
書き換えて実行する場合の注意点等々
※サブディレクトリを検索したい場合は、glob.glob()あたりを書き換えてrecursiveオプションを有効にしてください。
※google以外の類似画像検索にも使いまわせるかも?。
ソースコード
プログラミングスキルがクソ雑魚ナメクジなので意味不明な処理がありそうです。
短いブラウザの方は除いて、一応コメント書いてるので参考にしてください。
search_by_image_by_google_multi.py
import requests as req
from bs4 import BeautifulSoup as bs
import re
import os
import urllib.request
import urllib.error
import glob
from tqdm import tqdm
from multiprocessing import Process
import multiprocessing
PIC_NUM = 3
DIR_NAME = 'large_pic'
def main():
fetchurls = []
filelist = glob.glob('*.png')
[filelist.append(l) for l in glob.glob('*.jpg')]
filelist.sort()
print(filelist)
print('ファイルアップロード中...')
pbar_png = tqdm(total=len(filelist))
for filename in filelist:
fetchurls.append([upload(filename),filename])
pbar_png.update(1)
pbar_png.close()
headers = { #UA偽装しないと検索結果がもらえません
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
}
print('画像保存中...')
process_list = []
for fetchurl in fetchurls:
process = Process(
target=download,
kwargs={
'fetchurl': fetchurl,
'headers': headers,
})
process.start()
process_list.append(process)
for process in process_list:
process.join()
def download(fetchurl,headers):
soup = get_content(fetchurl[0],headers)
psurl = get_picsearchurl(soup,fetchurl[1])
if not psurl==False:
soup = get_content(psurl,headers)
picurls = get_pic_url(soup)
save_pic(picurls,fetchurl[1],headers)
def upload(filename):
url = "https://www.google.co.jp/searchbyimage/upload" #googleの類似画像検索を使うにはここにアップロード
multipart = {'encoded_image': (filename, open(filename, 'rb')), 'image_content': ''} #multipart/form-dataの形式らしい...
response = req.post(url, files=multipart, allow_redirects=False)
fetchurl = response.headers['Location']
return fetchurl
def get_content(url,headers): #検索結果をgoogleさんから頂いてきます
res = req.get(url,timeout=10000,headers=headers)
soup = bs(res.content,'html.parser')
return soup
def get_picsearchurl(soup,name): #画像のみの検索結果のURLを返します
pic_search_urls = soup.find(class_='O1id0e')
if re.findall('この画像の他のサイズは見つかりません。',str(pic_search_urls))==[]:
pic_search_url = pic_search_urls.find('a').get('href')
psurl = 'https://www.google.co.jp'+pic_search_url
return psurl
else:
print(name,'の他のサイズは見つかりませんでした。')
return False
def get_pic_url(soup): #類似画像検索の画像検索結果(画像が羅列される方の結果)の画像URL"リスト"を取得します。re.findallの(?:jpg|png)をpngに置換すればpng画像に絞れます
tmp = str(soup)
urls = re.findall(r'"https?.+\.(?:jpg|png).*",\d{3,},\d{3,}',tmp)
return urls
def save_pic(urls,filename,headers): #先頭URLの画像を./DIR_NAMEに保存します。最初の被検索画像取得をrecursiveにするならこの保存URLは上階層とかに変えたほうがいいです
for num in range(PIC_NUM):
try:
url = [s.strip('\'\" ') for s in urls[num].split(',')]
if int(url[1])>576:
tmp_name = filename.split('.')
url_extension = os.path.splitext(url[0])
ext = re.sub(r'\.','',str(url_extension[1]))
ext = re.sub(r'\W.*','',ext)
path = DIR_NAME+'/'+tmp_name[0]+'_'+'{0:02d}'.format(num)+'.'+ext
dir_exist = os.path.isdir('./'+DIR_NAME)
if not dir_exist:
os.mkdir('./'+DIR_NAME)
file_exist = os.path.isfile(path)
if not file_exist:
try:
request = urllib.request.Request(url[0], headers=headers)
with urllib.request.urlopen(request) as web_file, open(path, 'wb') as local_file:
local_file.write(web_file.read())
except urllib.error.URLError as e:
print(e)
else:
print('低画質画像しか見つからなかったため',filename,'を保存しませんでした\n')
except:
pass
if __name__ == '__main__':
multiprocessing.freeze_support() #windows上でmultiprocessingするため(exe用)
main()
search_by_image_by_google.py
import requests as req
from bs4 import BeautifulSoup as bs
import re
import os
import urllib.request
import urllib.error
import glob
from tqdm import tqdm
PIC_NUM = 3
DIR_NAME = 'large_pic'
def main():
fetchurls = []
filelist = glob.glob('*.png')
[filelist.append(l) for l in glob.glob('*.jpg')]
filelist.sort()
print(filelist)
print('ファイルアップロード中...')
pbar_png = tqdm(total=len(filelist))
for filename in filelist:
fetchurls.append([upload(filename),filename])
pbar_png.update(1)
pbar_png.close()
headers = { #UA偽装しないと検索結果がもらえません
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
}
print('画像保存中...')
for fetchurl in fetchurls:
print(fetchurl[1])
soup = get_content(fetchurl[0],headers)
psurl = get_picsearchurl(soup,fetchurl[1])
if not psurl==False:
soup = get_content(psurl,headers)
picurls = get_pic_url(soup)
save_pic(picurls,fetchurl[1],headers)
def upload(filename):
url = "https://www.google.co.jp/searchbyimage/upload" #googleの類似画像検索を使うにはここにアップロード
multipart = {'encoded_image': (filename, open(filename, 'rb')), 'image_content': ''} #multipart/form-dataの形式らしい...
response = req.post(url, files=multipart, allow_redirects=False)
fetchurl = response.headers['Location']
return fetchurl
def get_content(url,headers): #検索結果をgoogleさんから頂いてきます
res = req.get(url,timeout=10000,headers=headers)
soup = bs(res.content,'html.parser')
return soup
def get_picsearchurl(soup,name): #画像のみの検索結果のURLを返します
pic_search_urls = soup.find(class_='O1id0e')
if re.findall('この画像の他のサイズは見つかりません。',str(pic_search_urls))==[]:
pic_search_url = pic_search_urls.find('a').get('href')
psurl = 'https://www.google.co.jp'+pic_search_url
return psurl
else:
print(name,'の他のサイズは見つかりませんでした。')
return False
def get_pic_url(soup): #類似画像検索の画像検索結果(画像が羅列される方の結果)の画像URL"リスト"を取得します。re.findallの(?:jpg|png)をpngに置換すればpng画像に絞れます
tmp = str(soup)
urls = re.findall(r'"https?.+\.(?:jpg|png).*",\d{3,},\d{3,}',tmp)
return urls
def save_pic(urls,filename,headers): #先頭URLの画像を./DIR_NAMEに保存します。最初の被検索画像取得をrecursiveにするならこの保存URLは上階層とかに変えたほうがいいです
for num in range(PIC_NUM):
try:
url = [s.strip('\'\" ') for s in urls[num].split(',')]
if int(url[1])>576:
tmp_name = filename.split('.')
url_extension = os.path.splitext(url[0])
ext = re.sub(r'\.','',str(url_extension[1]))
ext = re.sub(r'\W.*','',ext)
path = DIR_NAME+'/'+tmp_name[0]+'_'+'{0:02d}'.format(num)+'.'+ext
dir_exist = os.path.isdir('./'+DIR_NAME)
if not dir_exist:
os.mkdir('./'+DIR_NAME)
file_exist = os.path.isfile(path)
if not file_exist:
try:
request = urllib.request.Request(url[0], headers=headers)
with urllib.request.urlopen(request) as web_file, open(path, 'wb') as local_file:
local_file.write(web_file.read())
except urllib.error.URLError as e:
print(e)
else:
print('低画質画像しか見つからなかったため',filename,'を保存しませんでした\n')
except:
pass
if __name__ == '__main__':
main()
search_by_image_webbrowser_by_google.py
import requests as req
import webbrowser
import glob
from tqdm import tqdm
def main():
num = 0
urllist = []
filelist = glob.glob('*.png')
[filelist.append(l) for l in glob.glob('*.jpg')]
filelist.sort()
print(filelist)
url = "https://www.google.co.jp/searchbyimage/upload"
for filename in filelist:
multipart = {'encoded_image': (filename, open(filename, 'rb')), 'image_content': ''}
picurl = get_page_url(multipart,url,filename)
if num>0:
print('Enterキーで次を表示します。\n')
input()
num += 1
web_open(picurl)
print('検索が終了しました\nEnterキーで閉じます\n')
input()
def get_page_url(multipart,url,filename):
response = req.post(url, files=multipart, allow_redirects=False)
fetchUrl = response.headers['Location']
return [fetchUrl,filename]
def web_open(url):
print(url[1])
webbrowser.open(url[0])
if __name__ == '__main__':
main()

コメント