

今回は結構グレーな記事です。
リバースエンジニアリングは利用規約で禁止されています。この記事内の記述を実行した事によるいかなる損害も補償しません。すべて自己責任の元で行って下さい。というか、「指揮官、こんなことしちゃだめだぞ…」(CV.堀籠沙耶)
また悪用は厳禁です。課金アイテムを扱いたいならダイヤ購入もお忘れなくにゃ。
文章の口調がところどころ違いますが、追記に追記を重ねたキメラ記事なので、更新時期によってデスマス口調だったりそうじゃなかったりしてるってだけです。キニセズヨンデネ。
追記
アプリケーションのバージョンアップに伴い、旧データの一部(スキンなど)がobb内に移動することがあります。obbファイルはapkファイルを入手(apk downloaderやGoogle Play以外のサイトなどを利用するなどして可能)した後展開することで入手できます。(NOXで/Android/obb/com.~ を探しても見つけられます。) obbファイルを入手したら同様に展開することでいつものフォルダの階層を見つけられるはずです。
やりたいこと
「これが君の望んでいる海戦(ロマン)」でお馴染みの某スマホゲーから持ってきたデータを復号して画像やL2DをGETし鑑賞。
もちろんGETした画像を配布するのはNG。あと課金アイテムの場合はちゃんと課金しよね。
準備
まずは準備だけど前提としてPCは必須。スマホオンリーでは(多分)無理。持ってない人は買うか回れ右。OSはwin10を前提とするけど、win7やwin8でも出来るかもしれない。というか多分出来る。OS XとLinuxも出来るかも。
とりあえず前提として以下のソフトをインストールしてあるものとする。
- NoxPlayer
- Python 3.x
- pip
- visual studio
- Live2D Cubism
エミュレータだがこれはBlueStacksでもおk。データを持ってくるだけだからなんならAndroidスマホでも良い。データはapk内やスマホ内のfiles/AssetBundlesの中にある。これがどこにあるかは、、、頑張って探して下さい。多分すぐ見つかると思われ。見つけたらAssetBundlesごとPC内の適当な場所に放り込む。
Pythonはここからダウンロード。インストールの仕方はググって。(私が使ったのは3.7.2)
pipはここを参考にインストール。(もしかしたらPython 3インストール時に一緒にインストールされてるかも)
visual studioは適当にググってインストールして。
Live2D Cubismは公式からDLしてインストールするだけ。
以上で準備終了。
L2D抽出
11/01更新
ツールが古くなったためこちらを使用。
使い方は旧ツールと一緒なので下記をUnityLive2DExtractorに置き換えればおk。
まずはツールをダウンロード。
AzurLaneLive2DExtract(以下L2DE)
Buildする場合
適当に保存して解凍する。AzurLaneLive2DExtract.slnが見つけられると思うのでダブルクリックで実行。visual studioが立ち上がるので、Any CPUの左をReleaseにしてビルド>AzurLaneLive2DExtractのビルドを実行。L2DE-master/L2DE/bin/Release/L2DE.exeが出力されればおk。(L2DEは省略した記述)
Releaseから持ってきたらそのまま解答すればおk。
持ってきたデータのAssetBundles/live2d内のファイルをL2DE.exeにドラッグ&ドロップ。するとコマンドラインにログが表示され最後にDone!と書かれていたら復号完了。フォルダごと突っ込んでも処理してくれないのでそこは注意。コマンドラインはエンターキーを押すと終了出来る。
※〇〇_textureは差し替えテクスチャのみなので単体ではL2Dデータとしての復号は不可。
出力ファイルはlive2d/live2d内にフォルダごとに分かれて出力される。後はmoc3ファイルをLive2D Cubism Viewerで開いて鑑賞するなり、Unityに突っ込んで遊んだり個人使用の範疇で楽しみましょう。
追記:フォルダ名を大陸版から英語版に変換する
追記:2019/11/06
上記の方法でlive2dを出力すると画像のように大陸版のフォルダ名で出力されてどのフォルダがどの艦に該当するかわからない。
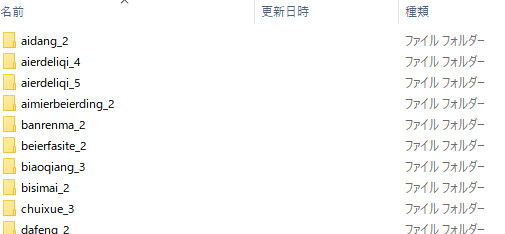
そこでこのフォルダ名を英語版に翻訳することにする。(日本語版にしないのは辞書がない関係上。日本語辞書をcsv形式で作れば日本語に変換することもできる。日本語辞書を作るとは言ってない中国語(漢字)-英語-日本語辞書を作成するプログラムは作りました。詳しくはこっちの記事で。これを利用したファイル名変換は時間があるときに作ります。)
準備。
まずは辞書をダウンロードする。辞書はこちらのAzurLaneSDViewerから借りてくる。ダウンロードしたら適当な場所に解凍する。
もうひとつ極簡単なToolをここに公開したのでAL_DIRNAME_TRANSLATE.zipをDLして適当な場所に解凍する。(readmeに書いたがこのツールを実行して起こったことの責任は取れないのでそこんとこよろ)
Toolではnumpyをimportするので予め導入しておく。コマンドプロンプトを開いて以下のコマンドを入力するだけでおk。
pip install numpy
こっから作業。
解凍したAzurLaneSDViewer-gh-pagesのAzurLaneSDViewer-gh-pages/jsの中にあるcharData.jsをコピーして、ToolのAL_txt2csv.pyと同じ階層にペーストする。
AL_txt2csv.pyをダブルクリックして実行(ないしはコマンドプロンプトから実行)するとcharData.csvが作成される。これを辞書として使うことになるので、一度生成すれば元のcharData.jsが更新されない限り再度生成する必要はない。自分で辞書を更新する場合は、メモ帳等から「,」で区切って辞書データを追加したりExcelから追加したりして良い。
次にもう一つのAL_dirname_ch2en.pyをダブルクリックで実行する。「enter path.」と表示されるのでLive2Dを出力したフォルダのパスを入力する。上手く行けばフォルダ名が翻訳される。ただし辞書にないフォルダは「元のフォルダ名_ch」としてフォルダ名が変更されるので、手動で修正してあげよう。
最終的にこんな感じになればおk。

画像抽出
追記:2020年(Then Came) the Last Days of May
欲しい画像はおそらくローディング画像、SDのKANSEN画像、KANSEN画像の3種でしょうきっと。
これらはそれぞれloadingbg、shipmodels、paintingの中に入っている。故にこの3つのフォルダをどこか分かりやすい場所に放り込んでおく。
スチルもここの項目
loadingbg shipmodels スチルの場合
まずはここからAssetStudioをダウンロードする。ただし、またビルドをするのは面倒だと思われるのでビルド済みのものをダウンロードすれば良い。
AssetStudioGUI.exeを起動し、File>Load Folderからloadingbgまたはshipmodelsを選択する。すると読み込み始めるので暫し待つ。読み込み終わったらExports > All assetsで出力する。
出力は元フォルダ内のSprite、Texture2Dフォルダの中にpng形式でアウトプットされる。
スチルはgallerypicディレクトリに入っている。
なおローディング画面の画質は、Twitterから見つけた画像のが良かったりする。なんでやねん。
より高画質の画像をGoogle検索で探す場合はこっちの記事で紹介したツール使うとやや楽かも。
paintingの場合
こちらはloadingbg、shipmodelsと比べるとちょっと複雑。
まずはloadingbg、shipmodelsと同じようにしてAssetStudioでpng画像を出力。しかしこの画像はパズルのように各要素がバラバラに配置されてしまっている。よってそれを修正してやる必要がある。

旧版
そのためにAzurLane-PaintingExtractを使うことになるが、これの導入が結構面倒なのでひとつひとつ解説していく。
まずはAzurLane-PaintingExtractをここからDLする。
とりあえずこれまでのようにどこかに放り込んで解凍しておく。
次にこのアプリケーションを使うための準備をする。
コマンドプロンプトを起動して
python --version
と入力し、pythonのバージョンが3以上なのを確認したら、
pip install pit
でpitをインストール。同様にwxpython, pywin32もインストールする。
pip install wxpython
pip install pywin32
これでAzurLane-PaintingExtractを動かすためのライブラリ等を導入できた。(導入できてない場合はコマンドプロンプトから実行してあげると、「~が見つかりません」とか「~が定義されてません」という旨のエラーが吐かれるのでファイル名でググってライブラリを見つけインストールしてあげればおk。もしわからなければページ下部のコメントに書いてくれたら(気がついたときに分かる範囲で)答えます。)
次に先程解凍したAzurLane-PaintingExtractのフォルダ内部にあるAzurLanePaintingExtract.pyをダブルクリックで起動。するとウィンドウがポップアップする。
左上、アイコンの下にある文件をクリックし
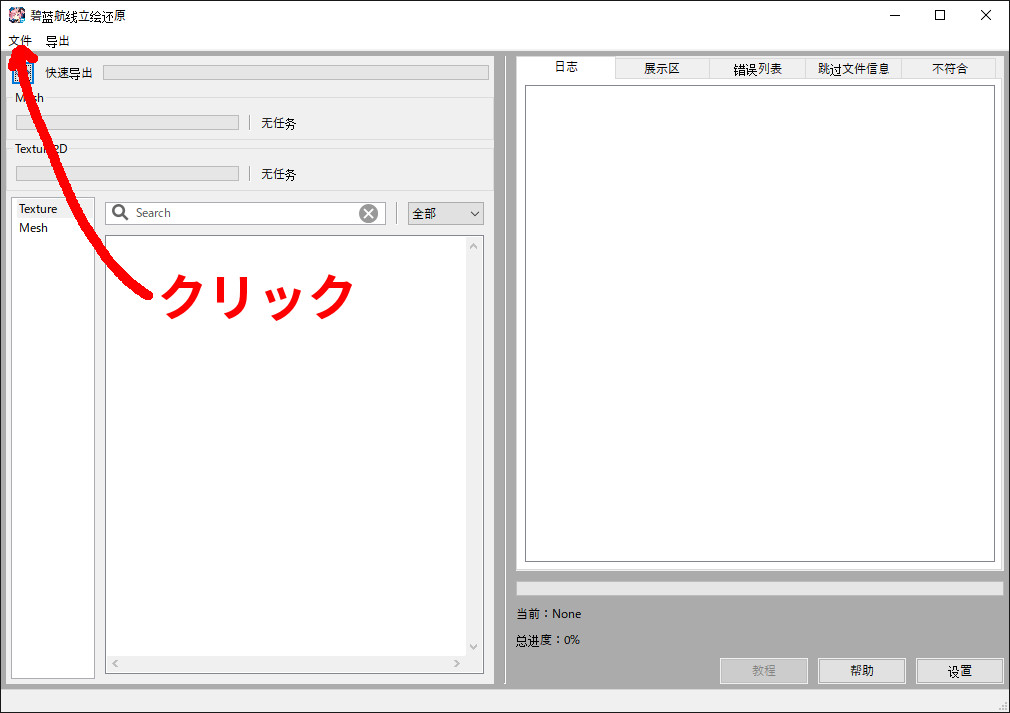
先程出力したTexture2DフォルダとMeshフォルダ内のファイルを全て選択し読み込ませる。この際Shift+左クリックで全選択すると楽。Texture2DフォルダについてはUISpriteも一緒に読み込ませてしまって問題ない。
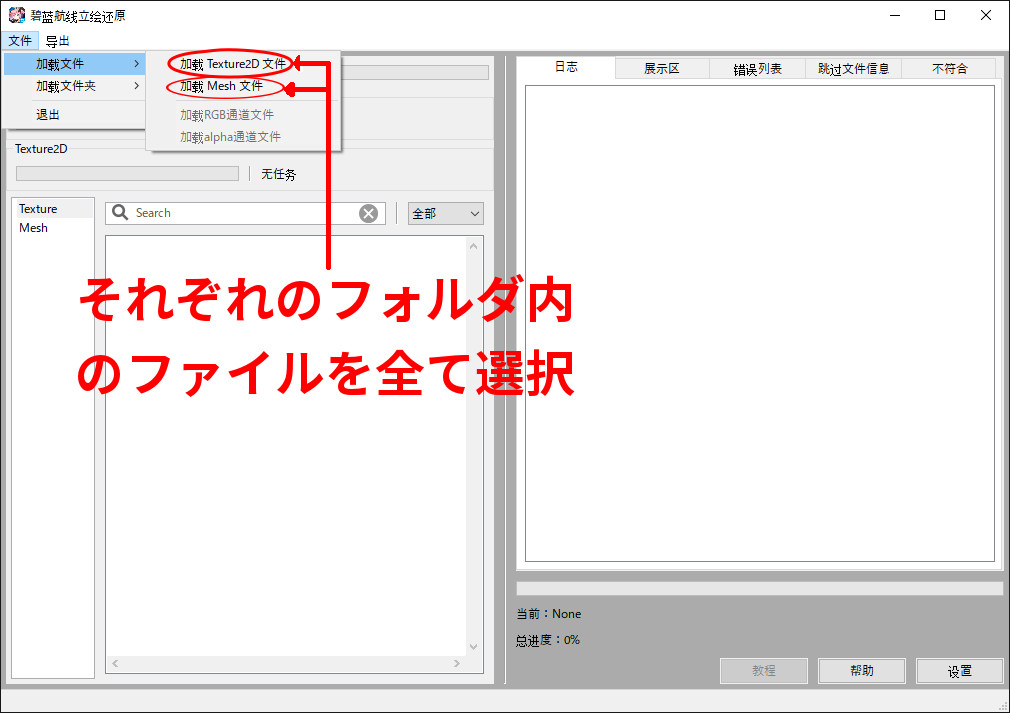
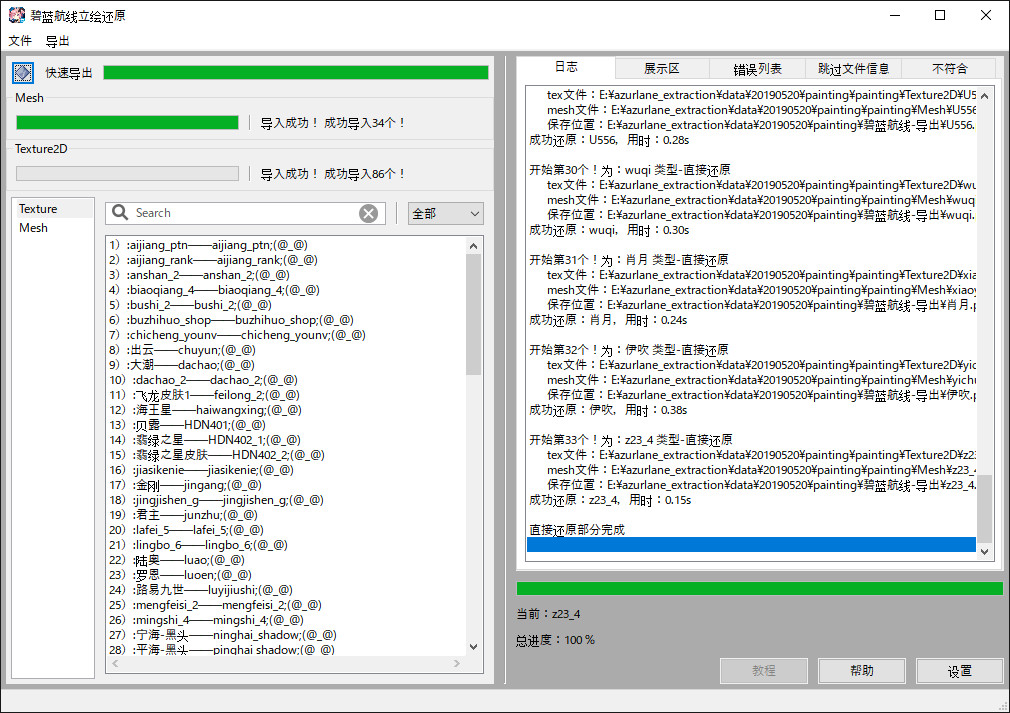
ファイルを選択したら文件の下のひし形アイコンをクリックすると次のようなウィンドウがポップするので、1でタブを選択し、2で出力先を決定し、3をクリックする。
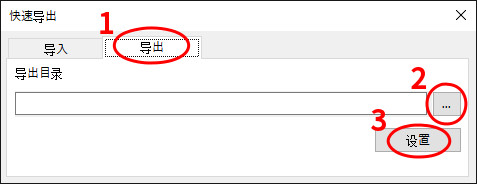
下の画像のようになんとか度:100%となったら出力が完了。選択したフォルダ内にある碧蓝航线-导出というフォルダに出力が格納される。
2020/05/09改定
コメントより教えていただきましたが、AzurLanePaintingExtractのNEW版、AzurLanePaintingToolがリリースされているのでそちらを使います。
コメント頂いたFORTRAN様ありがとうございました。そんな古い言語久々に聞きましたよ
こちらから最新バージョンをDLしてきます。
展開すると「AzurLanePaintingTool-1.4.4.1.exe」のような名前の実行ファイルがあるので実行します。
起動したら先にAssetStudioで展開しておいた「Mesh」「Texture2D」の2つをフォルダごとドラックアンドドロップ。下の画像のようになります。
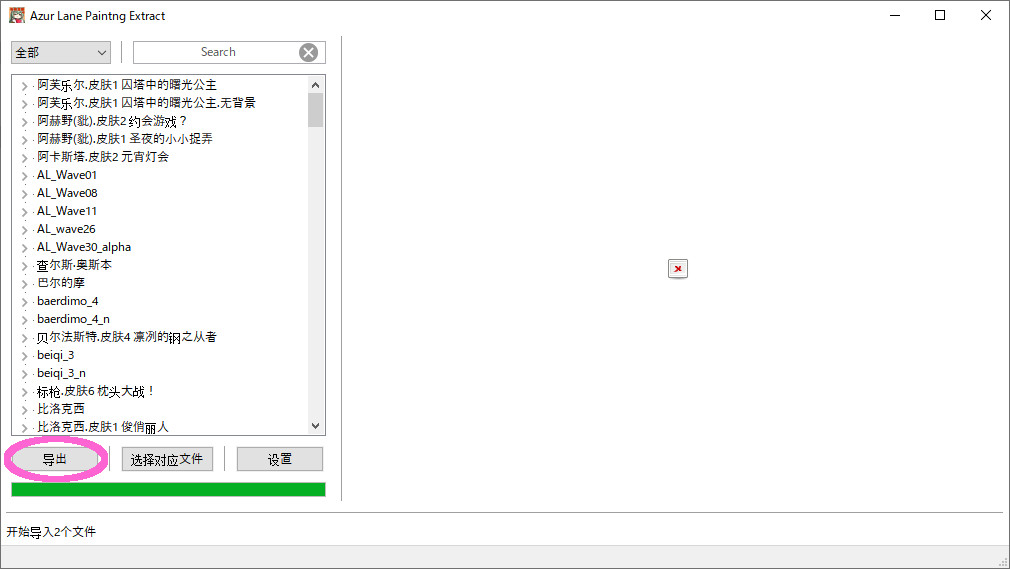
画像中の「导出」をクリック。
ポップアップウィンドウが表示されるので「导出全部可还原」を選択してOK。
すると保存場所を尋ねられるので、適当なフォルダを指定します。
出力が終わると指定したフォルダ内に「碧蓝航线-导出」が作成され、その中に画像が出力されます。
随分と簡単になりましたねこれは。
表情差分を出力できるようになったのでその解説もついでにしときます。
表情差分出力をしたい場合は、まず「paintingfaces」をAssetStudioで展開します。この際にソースフォルダごとに展開をしたいので、最新版0.14.38ならばOptions > Export options > Group exported assets byをcontainer pathに変更して出力します。(旧版の人はアップデートしてね)
「Mesh」「Texture2D」を放り込んだAzurLanePaintingExtractをにて表情ごとに出力したい艦について画像のように展開し、「为当前立绘添加附加表情」をクリック。
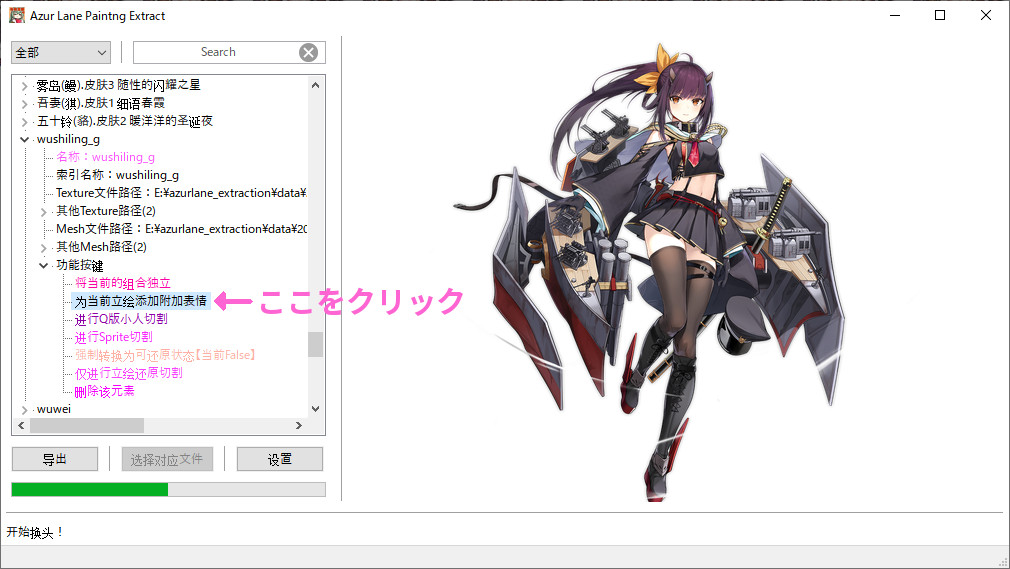
ウィンドウがポップアップしてくるので、「立絵座標」の「左上角横座標」と「左上角縦座標」の数字を調整してKAN-SENの顔が表示されるようにしておきます。この際、ウィンドウ下部の「歩長」を変更しながら、数字入力部でマウスホイールを使って調整すると楽です。
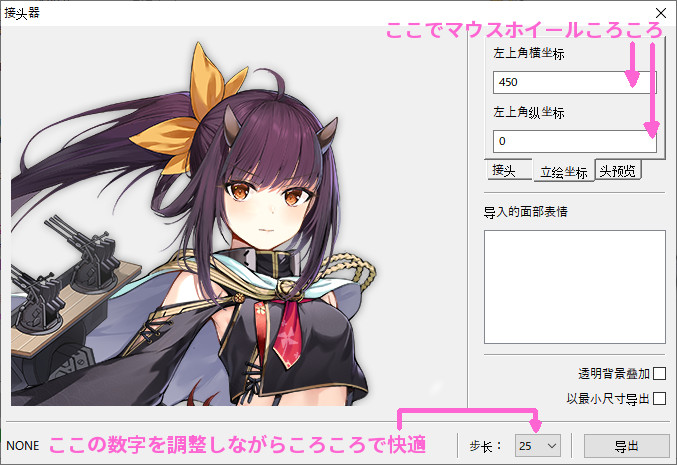
ある程度場所を合わせたら、「导入的面部表情」に、先程出力した「paintingfaces」の画像を(使う分だけ)ドラッグアンドドロップ。
ファイルが取り込まれると、ファイル名が表示されるのでとりあえずどれか一つをダブルクリックします。
すると左上の角の座標(0,0)の位置に先程の画像がオーバーレイ表示されます。(先程座標を調整した部分も一番左のタブに変更されて、そこにも表情差分が表示されます。)
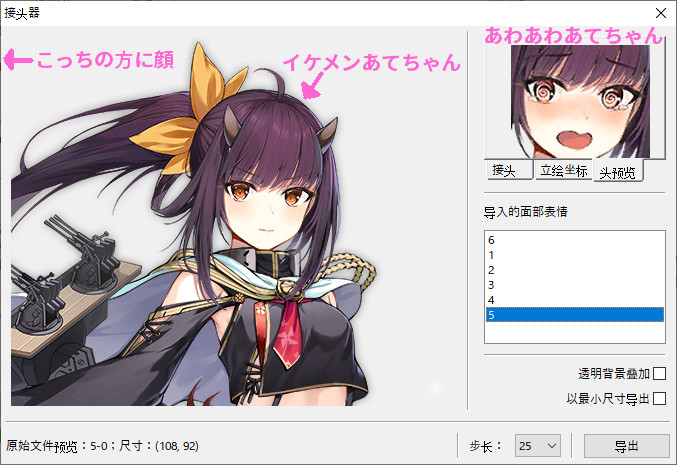
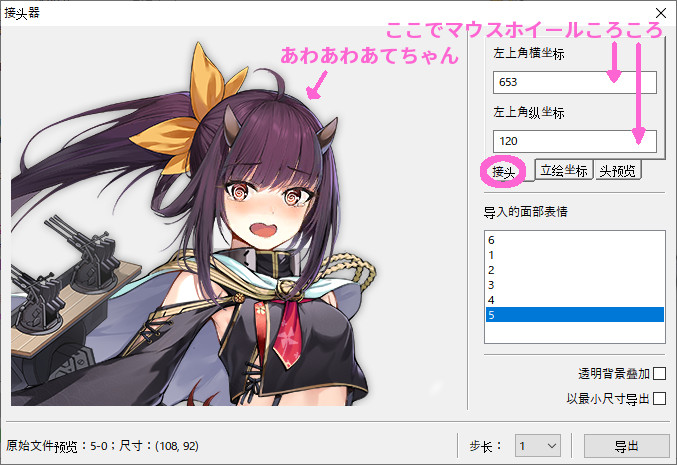
「接头 」をクリックして表情差分画像の座標を調整するタブに切り替えます。
先程表示場所を変えたときと同じように、マウスホイールコロコロで顔の位置を調節して合わせましょう。
やり方としては25間隔で大雑把に縦横合わせて、最後に1ピクセルずつの微調整をする感じが良いと思います。
この際、線の多い髪の継ぎ目が滑らかにながるよう意識して調整すると調整しやすい気がします。
あとは出力するだけです。
右下の「导出」をクリックして、「导出全部相同尺寸表情組合」を選択しOKをクリックすると出力先をきかれるので適当なフォルダを選択して完了です。
ちなみに他にもいくつか機能が追加されているようです。
私が使う予定はないのでここで紹介はしませんが、製作者さんがビリビリ動画のブログ(?)で解説しているので気になった方はどうぞ。(中国語ですが、日本語と英語の2種類に翻訳して比べながら読み進めればなんとか理解できるかと…)
追記1:音声・音楽ファイル抽出
アz…某スマホゲーをプレイしたことがあるのならば、音声・音楽ファイルの大部分はapk内ではなく別途data内に追加DLをしていることを知っているはずである。したがって音声ファイルを抽出したい場合はapkと追加データの両方を持ってくる必要がある。
apkはスマートフォンから抽出してもよいが、それよりはapkpure.comから直接PCにダウンロードしてくる方が遥かに楽。DLしている間に追加データの方から/files/AssetBundles/cueを適当な場所に放り込んでおく。
apkがダウンロードできたら拡張子をzipにして解凍。obbファイルが出力されるのでこれも解凍。(解凍は7zipが楽。)解凍したフォルダの中には色々データが入っているが、assets/AssetBundles/cueに目当てのものが纏まっている。ただし拡張子はbとなっている。この時点で音声データはapk、追加ファイル分全てをまとめてしまうと楽かもしれない。
このままでは音声ファイルとして聞けないのでbファイルを変換する。まずはhcaという拡張子に変換したいのでBGMToolboxを使う。ここからDLできる。
DLしたらVGMToolbox.exeを実行。以下の画像の用にCRI ACB/AWB Archive Extractorを選択したらファイルを全部投げ込む。ファイルごとにフォルダが出力されたらおk。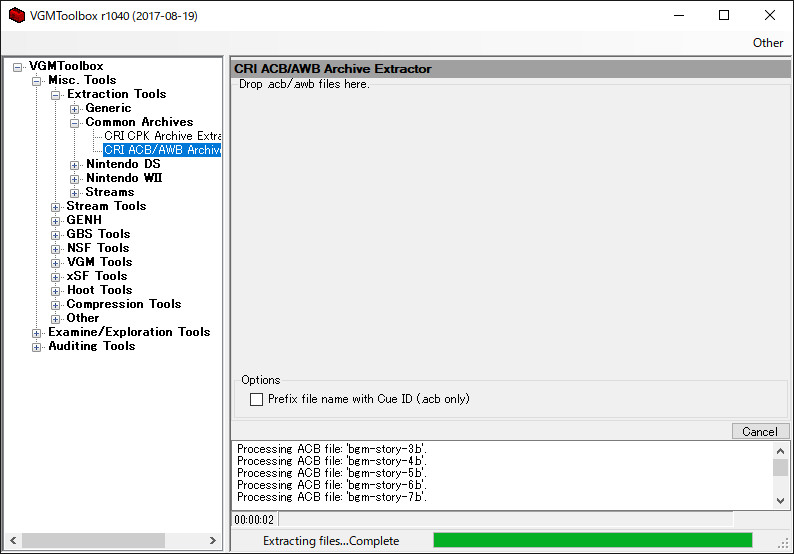
次はhcaファイルをwavに変換する。ツールはDereToreを使う。DLはここ。
ビルドしても良いが、面倒ならば、説明内のNightly Buildからビルド済みのものを持って来ると楽。
※コメントにてご指摘がありましたが、11/14現在DereToreのNightly Buildがダウンロードできなくなっています。したがってここから直接hca2wavをダウンロードしてコンパイルするか、私がコンパイルしたものをこちらからDLして下さい。
※リリースから最新版頂けばいい話ですね…
またUTF-8でない環境では文字化けが発生するそうなので、PowerShellにて
chcp
で、現在のコードページをメモっておき
chcp 65001
からUTF-8に変更して下さい。終わったら同様にして戻してかまいません。(メモるの忘れちゃったって人は932に変更すればおそらくもとに戻ります。)
さて、このツールで複合するにはキーが必要。キーはaキーとbキーがあり、ここから見つけられる。//でコメントアウトされた16進数表記のうち、前半分がbキーで後ろ半分がaキーである。つまりaキーは9~2までの8桁、bキーは0~Eまでの8桁がそれぞれ該当する。これをメモっておく。
windows powershellを起動。
cd E:\azurlane_extraction\data\20190527\cue\cue
でディクトリ を移動。ただし移動先はcueフォルダのある場所で、人それぞれ違うので書き換えること。
次に以下のコマンドでhcaをコンバートし、サブディレクトリ内にwavを出力する。hogehogeはさっき見つけたキーに、hca2wav.exeは環境にあったパスにそれぞれ書き換えること。
Get-ChildItem -Recurse -filter "*.hca" | % {
E:\azurlane_extraction\tool\deretore-toolkit-latest\Release\hca2wav.exe -a hogehoge -b hogehoge $_.FullName
}
全部を出力するには暫く時間がかかるので暫し待つ。私は寝た。
出力は得られたもののファイルツリーがぐちゃぐちゃなので整理する。
同じフォルダに一括配置する場合
まずは音声ファイルを同じフォルダ内に一括で置く場合。
Powershellで次のコマンドを実行する。
$src = "E:\azurlane_extraction\data\20190527\cue\cue"
$dest = "E:\azurlane_extraction\data\20190527\cue\cue\audio_output"
$num = 1
Get-ChildItem -Path $src -Filter *.wav -Recurse | ForEach-Object {
$nextName = Join-Path -Path $dest -ChildPath $_.name
while(Test-Path -Path $nextName){
$nextName = Join-Path $dest ($_.BaseName + "_$num" + $_.Extension)
$num += 1
}
$_ | Move-Item -Destination $nextName
}
$srcは音声ファイル入っているサブフォルダを配下に持つ親のフォルダ。
$dest出力フォルダ。
ファイル名+数字のファイルを出力できる。
フォルダごとに分けて出力する場合
Powershellで次のコマンドを実行する。
$src = "E:\azurlane_extraction\data\20190527\cue\cue"
$dest = "E:\azurlane_extraction\data\20190527\cue\cue\audio_output"
$List = (Get-ChildItem -Path $src -Filter *.wav -Recurse).FullName
foreach($a in $List){
$name =Split-Path -Leaf $a
$uppertDir0 = (Split-Path -Parent $a)
$uppertDir1 = (Split-Path -Parent $uppertDir0)
$uppertDir2 = (Split-Path -Parent $uppertDir1)
$Dname = Split-Path -Leaf $uppertDir2
$Dname = $Dname.Replace('_vgmt_acb_ext_', '')
$nextName = Join-Path $dest -ChildPath $Dname | Join-Path -ChildPath $name
if(!(Test-Path -Path (Join-Path $dest -ChildPath $Dname))){
New-Item -Path (Join-Path $dest -ChildPath $Dname) -ItemType Directory
}
Move-Item $a $nextName
}
さっきと同じく、$srcは音声ファイル入っているサブフォルダを配下に持つ親のフォルダ、$destは出力フォルダ。
フォルダごとに整理できている。
あとはwavをmp3に変換するなり自分で聞くなりご自由に。もちろん配布はNG。
追記2:データ差分を取る
よく考えたらファイラで更新日時ソートしてやればいいやん…
無駄なの
某スマホゲーでは追加データが毎週アプデごとに追加されていくが、古いデータがapkに格納されることは(滅多に)ない。ということは上記の手順では毎週全データを再度復号することになる。それは非常にアホらしいので、ファイル名の差分を取り、更新されたデータだけを復号出来るようにする。差分はpowershellで以下のスクリプトを使って取れば良い。
$new = "E:\azurlane_extraction\data\20190530\Azurlane\live2d"
$old = "E:\azurlane_extraction\data\20190527\live2d"
$out = "E:\azurlane_extraction\data\live2d"
$num = 1
$List0 = (Get-ChildItem -Path $new).FullName
foreach($a in $List0){
$namea =Split-Path -Leaf $a
$num = 0
$List1 = (Get-ChildItem -Path $old).FullName
foreach($b in $List1){
$nameb =Split-Path -Leaf $b
if($namea -eq $nameb){
$num = 0
break
}
else{
$num = 1
}
}
if($num -eq 1){
$nextName = Join-Path $out -ChildPath $namea
cp $a $nextName
}
}
newは更新後データのフォルダのパス、oldは古いデータ(1週間前)のフォルダのパスに書き換える。outはもちろん出力先。
またGet-ChildItemに-Recurseオプションを追加すればサブディレクトリまで検索してくれる。毎週全データの差分を取ったりするなら-Recurseオプションを使ったほうが良い。
追記3:OPを抽出
11/13追記
10月末から始まった大型イベントのポイント稼ぎが一段落したころ、そいえば今回流れたオープニングを保存してないことに気が付いた。このオープニングを保存したけれども、画面キャプチャだとなんだかなってなったので、今度はOPを抽出します。
まず目的のファイルを持ってきます。こいつはずばりそのままopeningという名前で、AssetBundles/uiの中に入ってました。
このopeningを例によって例のごとくAssetStudioで分離します。出力できるファイルの中でop_zh.txtというファイルが目当てのファイルなのでこれを確保します。
このop_zhをバイナリエディタで見てやると、以下の画像のようにusmという拡張子の動画ファイルであことが推察できます。

このままvgmtoolboxで通常の動画プレーヤで再生可能なファイル取り出したいところですが、残念暗号化されていて再生可能なファイルにはなりません。幸いにも(というか当然)暗号鍵は音声ファイルで使用したものと共通で使えるので、この鍵を使って復号します。
復号に使うツールは「CRID(.usm)分離ツール」で、こいつは製作者が公開してないっぽい?ですがツール名でググると二次配布されたものを見つけられます。自己責任で探してダウンロードしてきて下さい。
CRID(.usm)分離ツールを解凍して、crid.exeと同じ階層にop_zh.txtを投げ込みます。
次にコマンドプロンプトを起動してcdでカレントディレクトリをcrid.exeのあるディレクトリに指定します。(Cドライブ以外の場合は/dオプション使わないとディレクトリを変更できないので注意)
変更したらば
crid.exe -a hogehoge -b hogehoge -o "出力フォルダ名" "op_zh.txt"
で復号を実行します。(hogehogeは暗号鍵)
「op_zh.txt を分離中…」と表示された実行が終了して、出力フォルダ名の中にm2vとwavが入っていたら成功です。
ただしこのツールは分離ツールなので音声と動画が分離されてしまっています。視聴するにはMPC-HCを使ったり、予めaviutil等編集ソフトで合成する必要があります。
追記4:ゲーム内SNSデータ抽出
ゲーム内SNS画像の抽出は今までで一番簡単。
この画像は事前ダウンロードではなく、閲覧時にダウンロードしキャッシュしておく仕様になっている。
そのため、まずはゲームを起動してからSNS画面を表示させ、ゲーム内SNSの画像をすべて読み込ませる。
全部DLできたら、files/imgcacheの中にnotice_ins_1的な名前のディレクトリが出来ているはずなのでこれをそのまま持ってくる。
暗号化等は一切されていない生の画像ファイルなのでこれだけで終わり。
先に書いたが、事前配信はされていないので更新最終日にでも持ってくれば良い。
追記5:SDデータ
長くなりすぎるのでこっちで。
追記6:画像検索
手持ち画像のより大きいサイズをGoogleで検索したいときに使える便利(自称)ツール。
こっちの記事
最後に
ツールが揃っているおかげでかなり簡単に簡単にデータをぶっこ抜ける環境が整っている。しかし、環境が整っているからと言って気軽にやって良いわけではない。規約的にはおそらくアウトであり、当然法的にも問題となる可能性のあるかもしれない行為である。そんなわけでオススメ出来る行為ではないが、「どうしても俺はやりたいんだ!」って人は頑張れ。
ちなみにジャベリンの乳首テクスチャが埋もれてた。開発なにやってだ。

コメント
DareToreのNightly Buildのリンク先が存在していないようです。deretore-toolkit-latest.zipを別リンクで入手できるようにしていただくことは可能ですか?
ぶっこ抜きは規約違反だけど法的根拠は何もないですね。
ただのお願いに過ぎないから個人でやる分には当然合法だから好きにすればいいし(ただしBAN覚悟は必須)、当然それを赤の他人がとやかく文句言うのもお門違い。
製作者陣に指摘されたら即座にやめるべきだけど、無関係な第三者が結構攻撃してくるよねこういうの
ほんとここ数年変な人増えたなって思います
この方法でアズ○ン以外のアプリも抽出できますかね?
Unityで製作、独自の暗号化を行っていないゲームならばできるかもしれません。
僕は違うアプリで抽出したいのですが、追加DL分が何処にあるのかがわかりません。
どこに落とされるか教えて頂けませんか…?
一応解決しました。
お騒がせ致しましたm(__)m
(noxでapkをPCに転写、UABEを用いてファイルを全て解析し、その内からAudioClip種類を変換抽出。)
ただ、一つ問題なのは、
一番欲しかった曲が1っ出て来なかった事ですorz
欲しい画像のキャラはガチャで引かないとダメだったり音声だったらイベントを一度見ないと駄目でしょうか?
チュートリアルが終わった段階だとほとんどの画像データがありませんでした
ガチャで該当キャラクターを新規に引く必要はありません。
アズールレーンの場合はアプリ内の設定→アセットから追加データをダウンロードすれば音声は追加されます。
キャラ画像に関してはアプリを起動して最新版に保っておけば追加のダウンロードすら必要もありません。
お問い合わせいただいたファイルはobbファイルとは別に配置されているのでそれを探す必要があります。
Android(Nox Player含む)の場合は「/Andoid/data/com.yostarjp.azurlane/files/AssetBundles」下にあるフォルダに格納されていますので、AssetBundlesごと圧縮してPCにコピーしてから作業をすると良いかと思います。
iPhoneをお使いの場合はフォルダのパスが分かりかねますのでご自分でお探しいただくか、Nox Playerからダウンロードして上記のファルダにアクセスしてください
ご返信ありがとうございます。
com.yostarjp.azurlaneが別のフォルダにもうひとつあり、間違った方のフォルダを参照していました。
無事欲しいものを見つけることができました。
重ね重ねありがとうございます。
ブログ拝見させて頂きました.
質問なのですが,AzurLane-PaintingExtractフォルダ内部のAzurLanePaintingExtract.pyを起動させてもウィンドウが出てこず,以下のような画面が表示されたのちに消えてしまい先に進めません.
pipから必要なものはインストール出来ているはずなのですが,どうすれば解決出来るでしょうか?
ご教授お願いします.
/imgur.com/jJrnAY7
エラー文的にwxpythonかpythonのバージョンの問題な気がしますが…
面倒なことをしなくても、改定した記事内にて実行ファイルをダウンロードできるAzurLanePaintingToolを紹介しましたのでそちらをご利用いただければ楽に解決すると思われます。
AzurLanePaintingToolを利用したところ無事に修正できました.
ありがとうございます.あてちゃん可愛いです.
バラバラ画像の復元ソフト新しいverが出てますね。
教えていただきありがとうございます。記事を最新版に対応させました。
原神zip圧縮形式のデータをMacで抽出したいんですけど出来ますか?
私は試したことはないのでわかりませんが, Unityなのである程度似たような方法でやれるのかなとは思います. オーディオファイルの抽出ソフトもGithubに掲載されているのでそれらを参考にすると良いかもしれません.
最新版だと昔は存在したファイルが見当たらなくなってしまいました…。
上記の方法では新規のファイル以外は抽出は無理なのでしょうか?
セイレーン作戦以降
新規のファイル以外は見当たらなくなりましたけど見つけることはできるのでしょうか?
最新のファイル以外は抽出できないのでしょうか?
ジャベリンやエンタープライズといったキャラクターのファイルが見つかりませんが
他の場所に格納されているのでしょうか
最近某艦船ゲームのアプデでアセット関係の仕様が変わったようで、このページの方法だとLive2Dが抽出できなくなりましたが
このAssetStudioModGUIというAssetStudioの拡張版でLive2Dの抽出もサポートされており、こちらを使えば大丈夫なようです
https://github.com/aelurum/AssetStudio/releases